Les Caméras Numériques
Introduction
L’apparition de l’image numérique provient en grande partie de l’invention du capteur CCD, datant de 1969, et qui fut récompensé du prix Nobel de physique en 2009.
Le premier appareil photo numérique, le « mavica », fût lancé par Sony en 1981 et on estime que 21 ans plus tard, les appareils numériques représentait plus de 70% des ventes, surclassant ainsi les appareils argentiques.
Cependant, les appareils utilisés pour capter une image numérique sont très proche de ceux de type « argentiques ». En fait, nous retrouvons les mêmes éléments de bases tels que l’objectif, le viseur optique ou encore le déclencheur, mais la différence se situe au niveau de la surface photosensible : le film est remplacé par le capteur électronique qui transforme l’information lumineuse en un signal électrique.
L’essentiel de cette partie consistera donc à étudié ce composant, mais tout d’abord, rappelons quelques notions primordiales concernant l’image numérique.
Définitions de base
Le pixel (picture element) : c’est l’unité de surface de l’image numérique pouvant être assimilé à un carré d’une taille comprise entre 0,18 mm et 0,66 mm de côté. Dans une image en noir et blanc, chaque pixel représente un point tandis que dans une image en couleur, chaque pixel est constitué de trois points qui sont en fait les couleurs primaires permettant d’obtenir tout le spectre des couleurs.
La définition : c’est le nombre de pixel constituants l’image et qui indique la dimension de celle-ci. Par exemple, une définition de 1024*768 représente une image contenant 1024 pixels en largeur et 768 pixels en hauteur.
La résolution : c’est un rapport entre le nombre de pixel constituant l’image et ses dimensions. La résolution s’exprime en point par pouce ou ppp, sachant qu’un pouce fait 2,54 cm. De manière générale, la résolution peut être assimilé à la quantité d’information présente dans l’image : plus elle est élevé, meilleur est l’image.
Le format : il s’exprime par une valeur correspondant au rapport de la largeur par la hauteur de l’image : format = largeur / hauteur. Les images de télévision, tout comme celles du cinéma, sont en orientation paysage : leur format est donc supérieur à 1. A la télévision, le format normalisé à longtemps était le 4/3 mais récemment, on est passé au 16/9. Le cinéma autorise lui des formats beaucoup plus élevés, appelé formats cinémascopes (˜ 2,55).
A l'assaut des capteurs
Comme nous l’avons dit précédemment, le capteur électronique est l’élément essentiel d’une caméra numérique, permettant de transformer les rayons lumineux en un signal analogique. Il existe deux grandes familles de capteur : les types CCD (Charge Couple Devise) et les types CMOS (Complementary Metal Oxide Semi-conductor). En fait, le principe de fonctionnement est quasiment le même pour les deux technologies, et les différences se situent en particulier au niveau du transport de l’information.
La technologie CMOS est plus récente (début des années 80), et se retrouvent principalement dans le marché d’entrée de gamme (webcam par exemple). La technologie CCD est elle, dans la pratique, plus chère, plus complexe à fabriquer mais il est de coutume de dire qu’elle est de meilleure qualité même si l’écart tant à se réduire au cour de ces toutes dernières années.
Il existe aujourd’hui trois types principaux de capteurs CCD:
-Les CCD dit « plein cadre » (full frame en anglais) où l'ensemble de la surface contribue à la détection. Ce sont les capteurs les plus sensibles, mais également les plus lents et les plus facilement atteint par l'éblouissement.
-Les CCD dit « à transfert de trame » (full-frame transfer en anglais). Ils associent deux matrices CCD de même dimension, l'une exposée à la lumière, l'autre masquée. Cela permet de procéder à un transfert rapide de la matrice d'exposition vers la matrice de stockage puis à la numérisation de celle-ci en parallèle avec l'acquisition d'une nouvelle image. Le principal inconvénient est de diminuer par deux la surface photosensible (et donc de diminuer la sensibilité par deux).
-Les CCD dit « interligne ». Il s’agit là des capteurs CCD les plus complexes. Ils associent une photodiode à chaque cellule CCD. Ce sont eux qui sont principalement utilisés dans les photoscopes (appareils photo numérique).
Une étude de cas : le capteur CCD IT
Le capteur ccd « interligne » étant l'un des capteurs les plus utilisé dans le marché, analysons donc son fonctionnement afin de comprendre comment se réalise la captation d’une image numérique. Tout d’abord, il faut concevoir le capteur comme un immense damier contenant des centaines de milliers de cases.

Chaque case représente un pixel lui-même constitué d’une partie photosensible exposé à la lumière (environ 30% du pixel), et d’une cellule de stockage masqué. On appel registre vertical, l’ensemble des cellules de stockage d’une même colonne. Il existe autant de registres verticaux que de colonnes. Le registre horizontal (également appelé registre de sortie) est quand à lui unique, il est le dernier chainon avant que l’information ne sorte du capteur.
Structure du pixel :
Le pixel n’est pas uniquement constituer d’une partie photosensible, et il faut donc protéger ces surfaces afin de ne pas perturber l’information. C’est ainsi que les cellules photosensibles sont séparées par des CSG (« Channel Stopper Gate » ou « Stoppeur De Canal ») afin qu’il n’y ait aucun transfert de charge d’une cellule à l’autre. De plus, des ROG (« Read Out Gate » ou « Porte De Lecture ») séparent les cellules photosensibles de leurs cellules de stockage et ne s’ouvrent que lors du transfert de charges d’une cellule à l’autre.

Fonctionnement du capteur :
Dans un premier temps, les rayons lumineux atteignent les cellules photosensibles du capteur qui se chargent proportionnellement à l’intensité de ces rayons.
Ensuite, chaque cellule photosensible transmet la charge qu’elle contient à sa cellule de stockage (appartenant à un registre vertical).
Enfin, les charges sont transférées à travers les registres verticaux en direction du registre de sortie puis évacuées ligne par ligne en série.
Au final, nous pouvons résumer tous cela en un schéma :

Eléments et notions importants des capteurs CCD
Surfaces photosensibles :
Dans un capteur, la surface photosensible peut être une photodiode ou une cellule MOS (Metal Oxyde Semiconductor). Attention, nous retrouvons très fréquemment des cellules MOS dans des capteurs CCD et pas uniquement dans les CMOS (donc cellule MOS n’équivaut pas à capteur CMOS !!).
Analysons comment une cellule MOS transforme un rayon lumineux en une charge électrique proportionnelle à son intensité (le principe étant identique dans le cas d’une photodiode). Tout d’abord, observons la représentation simplifiée d’une cellule MOS :

Fonctionnement : la cellule MOS est polarisée ce qui créer un champ électrique à l’intérieur du substrat de silicium. Ce champ électrique repousse les charges positives (qui sont des trous) vers le fond de la cellule dopé P, et, par conséquent, une zone sans porteur de charge apparait : c’est ce que l’on appel la zone de déplétion. Si la cellule n’est pas polarisée, les trous occupent l’ensemble de l’espace et il n’y aucun électrons présent car le dopage du substrat est de type P. Ce n’est qu’en imposant une tension aux bornes de la cellule que l’on créer une zone de déplétion (dû au champ magnétique) et, plus la tension appliqué est élevé, plus la zone de déplétion est volumineuse.
Le fonctionnement de la cellule MOS repose maintenant sur l’effet photoélectrique découvert par Albert Einstein, qui montre qu’un matériau comme le silicium émet une paire électrons/trou lorsqu’il est exposé à un faisceau lumineux. Ainsi, lorsqu’un photon entre dans la couche de silicium du capteur MOS, une paire électron/trou va être éjecté, mais, à cause du champ magnétique présent dans la cellule, cette paire va être séparé : le trou est repoussé vers le fond de la cellule tandis que l’électron est attiré vers le haut de la cellule, par le métal. Du fait qu’il ne puisse pas traverser le silicium, l’électron se retrouve dans la zone de déplétion et ce n’est qu’au bout d’un certain temps, appelé temps d’intégration, que l’on considère les charges présentes dans cette zone comme étant proportionnelles à l’intensité lumineuse reçue. La cellule à donc convertie de la lumière en une charge électrique.
Transfert des charges :
Maintenant que nous avons l’information sous forme de charge électrique, observons comment réaliser le transport de cette information. Un peu plus haut, nous avons vu que les charges parcouraient le registre vertical puis horizontal avant de sortir du capteur. En fait, les cellules de stockages constituants ces registres ne sont rien d’autres que des cellules MOS, dont le fonctionnement ne nous est plus étranger.
Nous savons que plus la tension de polarisation d’une cellule MOS est importante, plus sa zone de déplétion est vaste. C’est grâce à ce principe que nous pouvons transférer les charges d’une cellule à une autre :
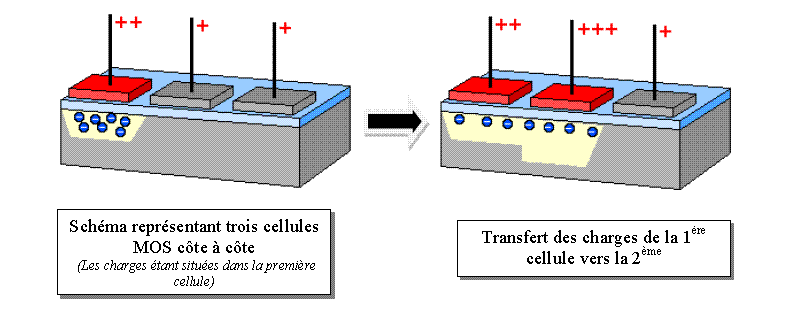
En appliquant une tension plus importante sur la deuxième cellule, une zone de déplétion plus volumineuse se créer et attire les électrons présents dans la première cellule. En fait, le fait d’avoir différentes polarisations au niveau de deux cellules proches engendre un champs électrique qui réalise ce déplacement d’électrons. Il ne nous reste plus qu’à répéter cette opération autant de fois que nécessaire afin de transférer les charges jusqu’au registre de sortie. L’ensemble des changements de tensions est assuré par des horloges (« clock »). Leur rôle est primordial, puisqu’il ne faut pas transférer les charges trop rapidement au risque de fausser l’information ni trop lentement car cela engendrerait une perte de temps au niveau de l’enchaînement des actions, ce qui est également néfaste car le temps d’exposition ne doit pas être trop important.
Au final, nous avons réussi à capter une image puisque chaque ligne sortant du registre horizontal (ou final) représente une ligne de l’image. Cependant, notre image captée est pour l’instant en noir et blanc, car les cellules photosensibles se chargent en fonction de l’intensité de la lumière reçue et non par rapport à sa fréquence, équivalente à sa couleur. Il va donc falloir trouver un moyen nous permettant de capter une image en couleur (voir chapitre intitulé "Un peu de couleur").
Les capteurs CMOS
Les capteurs CMOS (« Complementary metal oxide semi-conductor » en anglais) sont basés sur l'APS (« Active Pixel Sensor » en anglais ). En effet, contrairement aux capteurs CCD, sur un CMOS, la conversion en voltage des électrons stockés dans le puits de potentiel est faite directement au niveau de chaque pixels. Ils sont plus complexes à fabriquer mais sont produits selon des techniques classiques de micro-électroniques et de ce fait peuvent avoir des dimensions importantes (24 mégapixels). On peut voir sur le schéma ci-dessous qu'au niveau de chaque pixel, on trouve déjà un nombre important de composants électroniques.

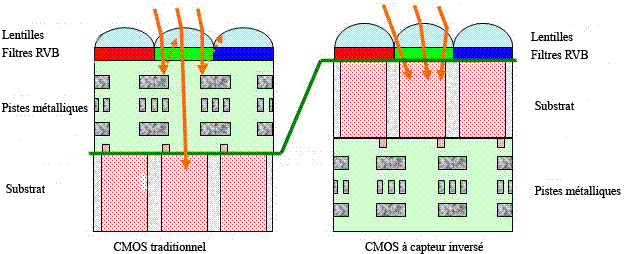
Sur un CMOS, chaque pixel est adressable individuellement par l'intermédiaire d'un adressage classique de type ligne-colonne. On voit sur cette image prise au microscope électronique une vision en coupe d'un APS :
Cette technologie réduit la perte de rayons à forte incidence puisqu'ils n'ont plus à traverser le tunnel di-électrique. Mais elle présente d'autres problèmes comme générer un bruit électronique important ou encore d’engendrer un nombre de pixels défectueux plus important.
Un peu de couleur :
Il existe deux méthodes différentes nous permettant d'obtenir une image couleur. Ces deux méthodes sont appliquable sur tous les types de capteur (CMOS comme CCD).
1ère solution : utilisation d’un filtre :
Cette solution consiste à appliquer un filtre composé des trois couleurs primaires (rouge, vert et bleu) et qui à pour conséquence de ne laisser passer qu’une couleur à chaque cellule photosensible. Il existe plusieurs types de filtre, avec différentes organisation des couleurs, mais le plus utilisés reste le filtre de Bayer :

Un pixel est donc maintenant composé de 4 surfaces photosensibles : une pour le bleu, une pour le rouge et deux pour le vert. Dans la réalité, notre oeil est plus sensible au vert (par rapport au bleu et au rouge), et c’est donc par imitation de cette réalité que le filtre laisse passer plus de vert. En appliquant cette méthode, nous obtenons bien une image en couleur, cependant le fait d’utiliser 4 surfaces photosensibles pour un pixel diminue sensiblement la résolution du capteur. 2ème solutions : utilisation de trois capteurs : Cela revient à filtrer les trois couleurs primaires afin d’utiliser un capteur par couleur.

Le séparateur optique (ensemble de prisme, de miroir, de miroir dichroïque, ...) permet d’aiguiller et de filtrer la lumière vers les CCD. Une fois que chaque couleur primaire a était aiguiller vers un des trois capteurs, les images issues de ces capteurs vont être converties en trois signaux électrique qui ne se rejoindront qu’après une série de test visant à les corrigé, c’est ce que nous allons voir juste après.
Après le capteur :
Dans les premières caméras numériques, il arrivait que l’on exploite directement le signal issu du registre horizontal qui est un signal analogique. Cependant, est pour tout un tas de raisons, il est préférable de convertir ce signal en un signal numérique, composé uniquement de 0 et de 1, qui possède l’avantage d’autoriser des traitements complexes et élevé sans que l’information ne soit affectée. Ainsi, en sortie du capteur on va chercher à transformer le signal en signal numérique le plus rapidement possible. Avant cela, le signal va être amplifié, puis va subir tout une série de petite retouche visant à corriger certaines erreurs comme des tâches au noir ou des problèmes au niveau des contours (correction des contours). Ce n’est qu’après ces étapes que l’on va le transformer à l’aide d’un convertisseur analogique/numérique. Dans le cas d’une caméra composé de trois capteurs, les trois signaux vont se rejoindre dans un circuit de modulation et de multiplexage pour être assemblé (étape complexe). Enfin, nous pouvons soit stocker ce signal en mémoire, soit l’utiliser via un ordinateur.
La convertion analogique/numérique
Les convertisseurs analogiques/numériques sont des montages électronique dont la fonction est de générer à partir d'une valeur analogique, une valeur numérique (codée sur plusieurs bits) qui est proportionnelle à la valeur analogique entrée. Le plus souvent il s'agira de tension électriques. Voici le cheminement de l'information depuis le capteur jusqu'à son stockage.

Voyons tout d’abord ce qu’est le gain analogique. Le gain analogique est appliqué à la sortie du capteur, il consiste à amplifier le signal. Cette amplification permet de gagner des niveaux de luminosité, mais elle amplifie également le bruit électronique généré par le capteur lui-même. Augmenter la sensibilité consiste donc inévitablement à augmenter le bruit électronique. On tentent toujours de diminuer au maximum les bruits inhérents au capteur, mais certains sont inévitables pour des raisons physiques.
L'étape suivante est optionnelle et consiste à essayer de réduire le bruit par une méthode « matérielle » . Le bruit généré par chacun des photosites est unique (c’est-à-dire propre à chaque photosite) mais en revanche il ne varie pas énormément d'une prise à une autre pour un photosite et un temps d'exposition donnés. L'idée consiste donc à faire une prise « noire » après la prise de la photographie elle-même. Cette prise « noire » permet de connaitre le niveau de bruit de chaque photosite en l'absence de tout signal lumineux. Ces valeurs sont alors soustraites photosite par photosite aux valeurs de la photographie elle-même.
Cette méthode marche surtout bien pour les temps d'exposition élevés, lorsque le bruit principal est effectivement le bruit lié au circuit du capteur lui-même.
Il faut noter que bien souvent la réduction du bruit a lieu après l'étape de conversion analogique/numérique et non avant, bien que cela n‘influe en rien sur le rendu final. Nous allons maintenant nous intéresser à la quantification du signal. L'opération de quantification consiste à transformer le signal analogique issu de chaque photosite en une valeur numérique. Le signal analogique a une valeur maximale qui s'exprime généralement en Volts. La question consiste à savoir comment discrétiser (discrétiser signifie que l’on remplace des relations relatives à des fonctions par des relations discrètes entre les valeurs prises par ces fonctions) ce signal sous forme numérique. Il s'agit donc de choisir le nombre de bits sur lequel on va représenter le signal. L'opération est ensuite une simple conversion par une règle de trois; si la valeur max du signal est Vmax et que nous choisissons de travailler sur n bits, alors le signal V observé sera transformé dans la valeur entière:
R = 2n V / Vmax.
La question est de savoir comment choisir la valeur de n. Il ne faut pas choisir une valeur de n trop petite car une partie de l'information serait perdue, mais il est aussi inutile de choisir une valeur trop grande. En effet, il existe une certaine imprécision sur la mesure du signal V qui est liée une fois de plus au bruit et il faut donc que le niveau de quantification (qui est égal à Vmax / 2n) soit toujours du même ordre de grandeur que l'erreur en question. Il s'agit là d'une bonne règle pour trouver la valeur de n la plus adaptée.
Stockage de l’information
Intéressons nous maintenant aux différents formats de fichier. Les données informatiques sont toujours stockées sous forme d'octets. Un octet correspond à un groupe de 8 bits. Une donnée sur 12 ou 14 bits devra donc être stockée sous la forme de deux octets consécutifs. L'ordre choisi (poids fort d'abord ou poids faible d'abord) de ces deux octets est généralement appelé « endianness ».

Il est possible de choisir l'une ou l'autre de ces deux manière de stocker les données. La version la plus simple du stockage des données consiste donc à écrire simplement sur la carte mémoire le flux complet en provenance du capteur. Pour un capteur de 16 méga-pixels, on aurait donc un fichier de l'ordre de 32 millions d'octets (32Mo).
Voyons maintenant quelle sont ces différents format de stockage. Il existe principalement 3 types de format de stockage: le format RAW, JPEG et TIFF. Observons plus en détail ces différents formats en étudiant leurs avantages et inconvénients respectifs: Voyons tout d’abord ce qu’est le gain analogique. Le gain analogique est appliqué à la sortie du capteur, il consiste à amplifier le signal. Cette amplification permet de gagner des niveaux de luminosité mais, du coup, elle amplifie également le bruit électronique généré par le capteur. Augmenter la sensibilité consiste donc inévitablement à augmenter également le bruit électronique. On tentent toujours de diminuer au maximum les bruits inhérents au capteur, mais certains sont inévitables pour des raisons physiques. L'étape suivante n'est pas indispenssable. Elle consiste à essayer de réduire le bruit par une méthode « matérielle » . Le bruit généré par chacun des photosites est propre à chaque photosite, mais en revanche, il varie peu d'une prise à une autre pour un photosite et un temps d'exposition donnés. L'idée consiste donc à faire, après la prise de la photographie elle-même, une prise dite « noire » . Cette dernière permet alors de connaitre le niveau de bruit de chaque photosite en l'absence de tout signal lumineux. Ensuite ces valeurs sont soustraites photosite par photosite aux valeurs de la photographie elle-même. Cette méthode offre des résultats satisfaisant surtout pour les temps d'exposition élevés (c'est-à-dire lorsque le bruit principal est celui lié au circuit du capteur ) . Bien souvent la réduction du bruit n'a pas lieu avant mais après l'étape de conversion analogique/numérique, bien que cela n‘influe en rien sur le rendu final. Nous allons maintenant nous intéresser à la quantification du signal. Cette opération consiste à transformer le signal analogique issu de chaque photosite en une valeur numérique. Généralement, le signal analogique a une valeur maximale qui s'exprime en Volts. La difficulté consiste à savoir comment discrétiser (discrétiser signifie que l’on remplace des relations relatives à des fonctions par des relations discrètes entre les valeurs prises par ces fonctions) ce signal analogique sous forme numérique. Cela revient donc de choisir le bon nombre de bits sur lequel on va représenter le signal. L'opération est ensuite une simple conversion. Appelons Vmax la valeur maximal du signal, et n le nombre de bits sur lequel on travaille. Alors, le signal V observé sera transformé dans la valeur entière: R (la valeur entière) = 2*n V / Vmax La difficulté est de choisir la bonne valeur de n. Il ne faut pas choisir une valeur de n trop petite car on risquerait de perdre de l'information, mais il est aussi inutile de choisir une valeur trop grande. En effet, il existe une certaine imprécision sur la mesure du signal V, qui est liée au bruit. Il faut donc que le niveau de quantification (qui est égal à Vmax / 2*n) soit toujours du même ordre de grandeur que l'erreur en question. De cette façon, on est sûre de trouver une valeur de n convenable.
Conclusion :
Pour l’imagerie numérique, le chemin parcouru par l’information entre l’entrée des photons dans le capteur numérique, et le stockage de l’image ou son affichage, est bien plus complexe que dans le cas d’une prise de vue argentique. Cependant, cette complexité est nécessaire pour pouvoir bénéficier de tous les avantages qu’offre l’imagerie numérique. En effet, les images numériques peuvent être retouchés a volonté, on peut aisément faire des grossissement, corrigé les défaut, ou encore introduire des éléments (les fameux effet spéciaux). Le faite qu’elles soient codées en langage binaire et donc qu’on puisse les manipuler depuis un PC offre des possibilités quasiment infini, ce qui est impossible à faire depuis des images argentiques. De plus, le numérique libère l’image de sont support papier, on peut donc inclure des milliers d’image, des heures de films sur de petites « clés mémoire » telle que les clés USB, ou encore envoyer, via internet, tous ces éléments en quelque secondes n’importe où dans le monde. Ces inombrables avantages ont poussé le numérique à s'imposer dans l'industruie du cinéma.Bibliographie
WEB :
http://www.larecherche.fr/content/recherche/article?id=5192
http://dp.mariottini.free.fr/Dossier/photo-numerique/photo-numerique.htm
http://fr.wikipedia.org/wiki/Photographie_num%C3%A9rique
http://astrosurf.com/luxorion/photo-numerique.htm
http://pages.videotron.com/danjean/
http://www.cndp.fr/archivage/valid/13489/13489-1230-1301.pdf
http://www.photo-lovers.org/
http://www.astrosurf.com/quasar95/exposes/imagesnumeriques.pdf
http://fr.wikipedia.org/wiki/Capteur_photographique
http://www.astrosurf.com/ursa/ccdbase.htm
http://www710.univ-lyon1.fr/~fdenis/club_EEA/cours/acq_capteurs.html
LIVRE :
« Les secrets de l’image vidéo », de Philippe Bellaïche